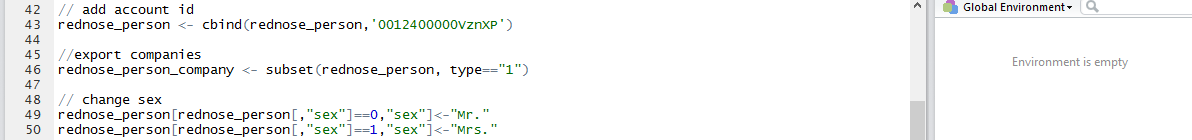
Import dat do Salesforce nebývá žádná věda. Ať už použijete standardního importního průvodce, který zvládne maximálně 50 000 záznamů nebo Workbench, který toho zvládne více, ale od určité chvíle začne hlásit chybu.
403 Forbidden – Invalid or missing required CSRF token
Poslední šancí je Data Loader, který si musíte sice nainstalovat na počítač, ale naimportuje cokoliv a v libovolném objemu.
Stačí připravit data, což je oblast, při které můžete narazit na problém. Jako já, když jsem dostal 500MB dat rozprostřených do 24 souborů ve struktuře, která naprosto neodpovídala té, kterou jsem potřeboval.

Normálně se to řeší v Excelu, použijete jeho funkce SVYHLEDAT, KDYŽ a další. Při 2,5 milionech řádků se vám ale trochu začne zadýchávat a ani rozkopírování funkcí přes tolik řádků není zrovna svižné.
Je tu Rko
Naštěstí jsem se minulý rok zúčastnil Data Fesťáku a naučil se alespoň základy R. Bez toho bych se asi pořádně navztekal a trvalo by mi to násobně déle.
Jsem naprostý amatér, který zvládne alespoň trochu své dotazy naformulovat a předhodit Googlu, takže během pár hodin, jsem ze souborů dostal, co jsem potřeboval a ve struktuře, kterou jsem potřeboval. Určitě jsem to nedělal ideálně, ale funguje to 🙂
Jaké funkce jsem použil?
rednose_person <- cbind(rednose_person,’0012400000VznXP’)
protože každá osoba musí být v SF napojena na firmu a není jednodušší cesta, jak ke všem řádkům přidat ID univerzální firmy
rednose_person_company <- subset(rednose_person, type==”1”)
subset vrací jenom záznamy, které splňují příslušnou podmínku (hodnotu ve sloupci type). Pokud naopak hledáte záznamy, které tam žádnou hodnotu nemají, použijte “is.na(type)”
rednose_person[rednose_person[,”sex”]==0,”sex”]<-“Mr.”
nahrazení jedné hodnoty jinou, v tomto případě nám ani tak nejde o pohlaví jako o to, jak toho člověk oslovit
rednose_person_personTit = merge( rednose_person_person,rednose_title,by.x = ‘title_id’,by.y = ‘id’)
spojení dvou souborů do jednoho, by.x a by.y určuje podle kterého sloupce, pokud se má párovat podle více sloupců použije se c( “sloupec1”, “sloupec2”). Další šikovné parametry jsou all.x a all.y = TRUE, které umí ve výsledném souboru nechat i řádky, které nemají odpovídající řádek v druhém souboru.
rednose_transfer$accnum <- paste( rednose_transfer$account_prefix,rednose_transfer$account_number,sep=“-„)
paste, pokud potřebujete spojit hodnoty z více sloupců do jednoho, v tomto případě do sloupce accnum.
rednose_address_subset <- rednose_address_compP[!duplicated(rednose_address_compP[,”person_id”]),]
pro nalezení duplikovaných řádků je duplicate, kontroluje duplicitu přes pole person_id. A vrací první z těch duplikovaných řádků
rednose_serazeno <- rednose_address_compP[order( rednose_address_compP$modified.x),]
po zmegrování se mi také stávalo, že se jinak seřadily řádky, než bych chtěl. Order to vyřeší
rednose_campaignitempart <- rednose_campaingwithanswers[-c(1:500000),]
pokud chcete ve výsledku jenom určitý počet řádků. Mínus na začátku říká, že těch prvních 500 000 se má vynechat, pokud by tam nebylo, tak se naopak použije prvních 500 000 řádků
rednose_person$criteria <- NULL
pokud z nějakého důvodu chcete vymazat konkrétní sloupec
names( rednose_person)[2] <- “název”
pro přejmenování druhého sloupce, abyste se v tom vyznali
write.csv(rednose_transferimppost,file=”transferpost.csv”, na=”“)
a konečně export výsledku do CSV souboru.
Objem dat
Rko se ani extra nezadýchalo a ty cca čtyři miliony řádků jsem zpracoval během hodinky či dvou. Nejhorší vždy bylo vymyslet jak spolu data souvisí, najít správnou funkci a zkontrolovat výsledek.
Vzhůru na import dat, u kterého je dobré myslet na několik věcí:
- je dobré si do záznamů uložit původní ID řádku, veškeré aktualizace dat vám pak půjdou snáze a nebudete muset dohledávat záznamy a párovat je – mimochodem ID záznamu v Salesforce je case sensitive, s čímž třeba Excel nepočítá a musí se to obcházet
- Data Loader (narozdíl od standardního importu v SF) umí párovat záznamy na základě polí typu External ID, ale umí to jenom při Upsertu dat (nikoliv při Update, jak by člověk čekal). Takže se buď pomodlete, nebo se ujistěte, že jiné záznamy se nevytvoří – z aktualizačního souboru vynechte povinná pole
V tom objemu dat, který jsem importoval, je ale nutné myslet ještě na něco – standardně můžete udělat 15 000 volání API za 24 hodin, což je taková neuchopitelná hodnota, která pro mě znamená něco přes milion záznamů zapsaných/aktualizovaných/exportovaných či smazaných. V nápovědě je to přesněji, ale i když jsem si Batch Size nastavil větší, tak to jelo po 200 záznamech.
Pokud potřebujete víc, musíte včas napsat na helpdesk, protože jim to standardně trvá dva dny a čtyři emaily s ujištěním se, ale nemají problém ten limit maximálně na dva týdny řádově navýšit.