 Akce Big Clean, která se konala v Národní technické knihovně v sobotu 19. 3. 2011, slibovala zajímavé výzvy i informace. Během jednoho dne se dozvědět jak z nestrukturovaných dat dostupných na webu i jinde získat něco, co je možné automaticky zpracovat, bylo lákadlo. Stejným lákadlem byly i přednášky na téma co pak s těmi daty a příklady praktického využití v nejrůznějších oblastech.
Akce Big Clean, která se konala v Národní technické knihovně v sobotu 19. 3. 2011, slibovala zajímavé výzvy i informace. Během jednoho dne se dozvědět jak z nestrukturovaných dat dostupných na webu i jinde získat něco, co je možné automaticky zpracovat, bylo lákadlo. Stejným lákadlem byly i přednášky na téma co pak s těmi daty a příklady praktického využití v nejrůznějších oblastech.
Akce měla dva paralelní bloky, takže je otázkou, který z nich mohl být zajímavější. Diskuze na téma otevřených dat ve veřejné správě podle všeho zajímavá byla (soudě podle dostupných zápisků a informací o zajímavých serverech). Stejně tak zajímavé mohlo být praktické odpoledne, v rámci kterého vzniklo hned několik zajímavých vyčištěných dat (opět zápisky na Google Docs).
Nicméně já jsem si vybral spíš ty teoretické přednášky na téma existujících nástrojů pro vytěžení a transformaci dat a jejich následné využití. Tempo mi chvílemi přišlo vražedné a zjistil jsem, že už se mnohdy vůbec nechytám.
Teoretická přednáška od Štefana Urbánka o analýze dat byla super. Třeba jsem se dozvěděl, na čem závisí kvalita dat – na jejich kompletnosti, přesnosti, důvěryhodnosti, konzistenci s ostatními zdroji a vhodné vazbě mezi zdroje a konečně aby byla aktuální. Přesnost je možné v mnoha případech měřit pocitově – třeba v odpoledním hackování webů se zjistilo, že v Praze je teplota -70 stupňů , což je zjevný nesmysl.
Ve zkratce ETL znamená E extrakci, což není žádný jednoduchý úkol. Když člověk vidí tabulku tak má pocit, že vyhrál, ale když se koukne na její zdroj tak mnohdy prohrává – spousta vnořeých tabulek v různém počtu úrovní, formátování pomocí stylů, občas hodnoty v jiném sloupci než jinde. Stejně tak nejsou výhrou data v MS Excel tabulce – lidé si občas několik buněk ohraničí čárou a považují ji za jednu velkou buňku, ale hned o pár řádek dál to mají zase jinak. T už je pak jednoduchá transformace a to jsem pochopil, že už je veskrze snadné.
Na závěr své prezentace ukázal server o veřejných zakázkách na Slovensku spolu s daty, na základě kterých ho dávají dohromady. Musela to být neuvěřitelná práce ty skripty připravit, ale výsledná data jsou hodně zajímavá.
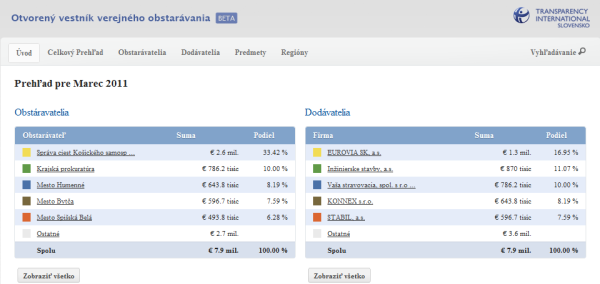
Příjemná byla přednáška Adama Javůrky o využití dat v žurnalistice, kde ukazoval jeden příklad za druhým a vždy řekl, co je na něm zajímavého a proč si ho vybral. Seznam všech příkladů je dostupný. Všechny mají několik věcí společných, jednou z nich je „wow effect“, tedy schopnost zaujmout. Toho je mnohdy dosaženo tím, že jsou nejdříve pečlivě vybraná data, třeba jako seznam všech mrtvých v Bagdádu během jednoho dne, přičemž samozřejmě vybrali pouze ten den, kdy jich zahynul dostatek. Mimochodem datoví žurnalisté prý data milují, protože nad nimi jde dělat nádherné vizualizace, které sice jsou mnohdy k ničemu, ale lidem se líbí a zabijí u nich čas.
Scrapping
Scrapping je vlastně získávání dat z webových stránek, při kterém by neměl příslušný web zjistit, že nejste člověk. Což jsem si nejdřív vyložil tak, že nemá hrozit aby mi podvrhnul data a posléze zjistil, že jde spíš o nezatěžování příslušného serveru. Takže šetřit požadavky, dát mezi ně prodlevy, respektovat robots.txt soubor a vůbec se chovat, jako kdybychom byli u někoho na návštěvě.
Pro scrapping existuje několik zajímavých nástrojů, které jsme prošli prakticky:
- ScraperWiki
- YQL
- Yahoo Pipes
- Google Docs
ScraperWiki
 Nejdřív jsme pronikli právě do tohoto nástroje, který je vlastně celý hostovaný na webu a může se volně využívat (pro komerční použití byste se „měli zeptat“).
Nejdřív jsme pronikli právě do tohoto nástroje, který je vlastně celý hostovaný na webu a může se volně využívat (pro komerční použití byste se „měli zeptat“).
Je zde dostupný market, kde můžete zadat požadavek na vyčištění dat nebo naopak nějaký splnit a vydělat si tím peníze. Podporují programování v několika různých jazycích a pravidelný běh olizování webu, takže data jsou hezky aktuální. Pomocí tohoto nástroje vlastně vznikla všechna data v odpolední sekci.
YQL
Yahoo Query Language staví na myšlence, že celý web je jedna velká databáze, pro kterou vytvořili upravené SQL příkazy. Funguje to neuvěřitelně krásně, data se transformují, spojují se výsledky z různých serverů a když s tím člověk trochu umí, tak získá neuvěřitelné množství vzájemně provázaných informací.
Pro omezování vrácených dat se používají XPath výrazy, které jsou překvapivě jednoduché (dosud jsem se s nimi nějak nesetkal).
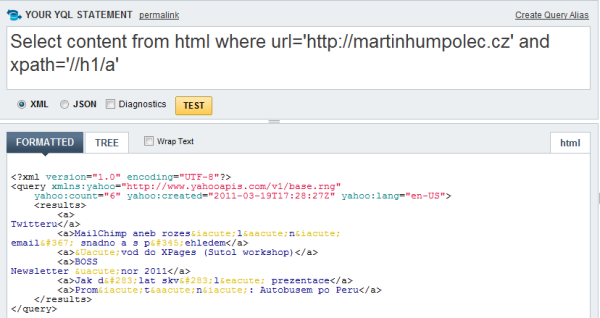
Yahoo Pipes
 S Yahoo Pipes jsem se potkal už před lety, ale zase úspěšně zapomněl, že existují. Úžasná myšlenka na kombinování dat z různých zdrojů, jejich filtrování, řazení, rozdělování a spojování a ve finále publikování v podobě jaké chci. Skvělé je, že člověk nemusí umět programovat, vše si natahá a podle některých ukázek v tom jdou dělat i celkem komplikované věci nebo naopak úžasné blbostičky.
S Yahoo Pipes jsem se potkal už před lety, ale zase úspěšně zapomněl, že existují. Úžasná myšlenka na kombinování dat z různých zdrojů, jejich filtrování, řazení, rozdělování a spojování a ve finále publikování v podobě jaké chci. Skvělé je, že člověk nemusí umět programovat, vše si natahá a podle některých ukázek v tom jdou dělat i celkem komplikované věci nebo naopak úžasné blbostičky.
Google Docs
Podle názvu produktu se to úplně nezdá, ale i Google Docs se dají použít na automatické stahování obsahu webu a nějaké operace nad výsledkem. Fíglem je použití funkcí ImportXml, ImportHtml, ImportData a ImportFeed spolu s již zmíněnými XPath výrazy a během pár chvil je ve vaší tabulce staženo to, co potřebujete a můžete nad tím provádět další operace.
Čištění dat
Pokud už člověk odněkud získá data, tak je potřeba je nějak hezky vyčištit. A na to jsou další nástroje, které mohou být neuvěřitelně mohutné (zvláště vzhledem k faktu, že jsou zdarma).
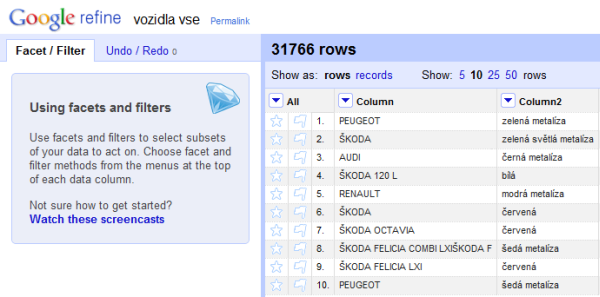
Google Refine
Google Refine je aplikace od Google, která je – naprosto překvapivě – nutná stáhnout a spustit z lokálního počítače. Potom se už spustí webové prostředí, ale všechny výpočty a operace probíhají na vašem počítači. Což může být plus ale i mínus.
Jakub Nešetřil z GoodData ho zjevně používat umí vzhledem k rychlosti s jakou data stažená z webu transformoval, čistil a řadil, aby získal nějaké rozumné výstupy. Pozorovat ho bylo fantastické, pár kliknutí, občas napsat nějaký regulární výraz, protože to je nejjednodušší cesta, a za chvíli jsme měli data, ze kterých bylo i něco vidět. Chtělo by to mít záznam přednášky nebo chvilku na prohlédnutí tutoriálů, možnosti použití jsou zjevně ohromné.
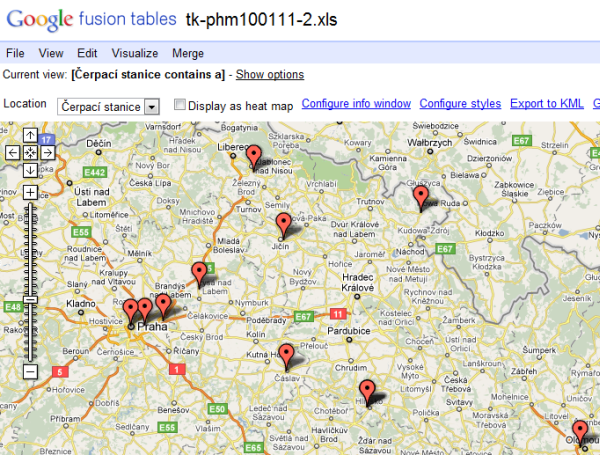
Google Fusion Tables
Další nástroj od Google, tentokrát webový. Do Google Fusion Tables se nahrají data (Excel nebo CSV, které může mít až 100MB) a pak už je možné si s nimi hrát. Možností to podle všeho nemá tolik jako Refine, je to spíš zaměřeno na vizualizaci. Takže stačilo nahrát soubor se záznamem kontrol čerpacích stanic a hned se dalo přepnout na mapu, kde jsou špatné pumpy nebo naopak na časovou osu, na které je vidět jak postupně kontroly šly. Velice pěkné a získání dat je otázka pár kliknutí.
Závěr
Velice povedená akce, na které jsem se seznámil se spoustou neznámých a mocných nástrojů a tipů jak převádět data mezi různými formáty snadno a rychle. Příjemné zjištění, že existuje spousta iniciativ na čištění dat a seznamování veřejnosti s hospodařením a fungováním státu i jednotlivých obcí nebo městských částí a současně trochu zklamání, že tyto akce nejsou koordinované a navzájem o sobě moc nevědí.
Prezentace z celé akce by měly být dostupné na stránkách konference a celou dobu byl také velice aktivní Twitter kanál #bigcleancz.
Na úplný konec ještě jeden server, který budu muset pořádně prozkoumat – Prezi, na tvorbu líbivých prezentací. Sledovat jak to animuje, točí se, zvětšuje a zmenšuje je nádherné, otázkou ovšem je, zda to trochu neodtahuje pozornost. Nicméně sledovat výuku matematiky v této prezentaci je fantastické.
Detailnější zápisky od lidí z GUG – { Link }